在當(dāng)今這個(gè)數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,“大數(shù)據(jù)”已成為一個(gè)無(wú)處不在的熱門詞匯。無(wú)論你是技術(shù)愛好者、企業(yè)管理者,還是希望轉(zhuǎn)行進(jìn)入數(shù)據(jù)領(lǐng)域的新手,理解大數(shù)據(jù)的基礎(chǔ)概念都至關(guān)重要。入門大數(shù)據(jù),并非意味著你必須立即掌握復(fù)雜的技術(shù)棧,而是先建立對(duì)核心概念和生態(tài)的整體認(rèn)知。以下是每一位大數(shù)據(jù)初學(xué)者都需要了解的5件基礎(chǔ)要事。
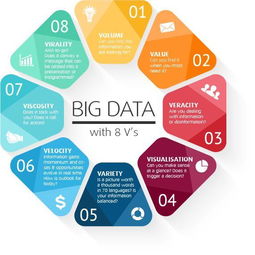
1. 理解大數(shù)據(jù)的核心“5V”特征
大數(shù)據(jù)的定義遠(yuǎn)不止于“數(shù)據(jù)量很大”。它通常由五個(gè)核心特征來(lái)界定,即“5V”:
Volume(大量):數(shù)據(jù)的規(guī)模極其龐大,通常達(dá)到TB、PB甚至EB級(jí)別,傳統(tǒng)工具難以處理。
Velocity(高速):數(shù)據(jù)產(chǎn)生的速度非常快,需要近乎實(shí)時(shí)地處理和分析,例如社交媒體流、物聯(lián)網(wǎng)傳感器數(shù)據(jù)。
Variety(多樣):數(shù)據(jù)格式多樣,包括結(jié)構(gòu)化數(shù)據(jù)(如數(shù)據(jù)庫(kù)表格)、半結(jié)構(gòu)化數(shù)據(jù)(如XML、JSON日志)和非結(jié)構(gòu)化數(shù)據(jù)(如文本、圖片、視頻)。
Veracity(真實(shí)性/準(zhǔn)確性):數(shù)據(jù)的質(zhì)量和可信賴度。海量數(shù)據(jù)中可能存在噪聲、不一致和不確定性,確保數(shù)據(jù)可信是分析的前提。
* Value(價(jià)值):這是最終目的。大數(shù)據(jù)本身并非目的,如何從海量、高速、多樣的數(shù)據(jù)中挖掘出洞察、預(yù)測(cè)趨勢(shì)、創(chuàng)造商業(yè)價(jià)值,才是關(guān)鍵。
理解這“5V”,能幫助你從本質(zhì)上把握大數(shù)據(jù)處理所面臨的挑戰(zhàn)和機(jī)遇。
2. 掌握從數(shù)據(jù)到價(jià)值的基本流程
處理大數(shù)據(jù)并非一蹴而就,它遵循一個(gè)清晰的流程管道:
1. 數(shù)據(jù)采集與存儲(chǔ):需要從各種源頭(網(wǎng)站、APP、傳感器等)收集數(shù)據(jù),并將其存儲(chǔ)在可擴(kuò)展、可靠的存儲(chǔ)系統(tǒng)中,如Hadoop HDFS、云對(duì)象存儲(chǔ)等。
2. 數(shù)據(jù)處理與集成:對(duì)原始數(shù)據(jù)進(jìn)行清洗、轉(zhuǎn)換、集成,將其轉(zhuǎn)化為可供分析的格式。這一階段可能涉及批處理(如使用MapReduce、Spark)或流處理(如使用Flink、Storm)。
3. 數(shù)據(jù)分析與挖掘:運(yùn)用統(tǒng)計(jì)分析、機(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘等技術(shù),從處理好的數(shù)據(jù)中發(fā)現(xiàn)模式、關(guān)聯(lián)和洞察。
4. 數(shù)據(jù)可視化與解釋:將分析結(jié)果以圖表、儀表盤等直觀形式呈現(xiàn),讓非技術(shù)人員也能理解,并據(jù)此做出決策。
了解這個(gè)端到端的流程,能讓你明白大數(shù)據(jù)項(xiàng)目中各個(gè)環(huán)節(jié)的角色和所需技術(shù)。
3. 熟悉主流的技術(shù)生態(tài)與工具
大數(shù)據(jù)領(lǐng)域擁有一個(gè)龐大且活躍的開源技術(shù)生態(tài)。入門時(shí),無(wú)需全部精通,但需要對(duì)核心組件有所了解:
存儲(chǔ)基石:Hadoop HDFS 是分布式文件系統(tǒng)的代表,為海量數(shù)據(jù)提供存儲(chǔ)基礎(chǔ)。
計(jì)算引擎:Apache Spark 是目前最主流的分布式計(jì)算框架,因其內(nèi)存計(jì)算特性,在速度和易用性上遠(yuǎn)超早期的MapReduce,支持批處理、流處理、機(jī)器學(xué)習(xí)和圖計(jì)算。
資源管理與調(diào)度:Apache Hadoop YARN 和 Kubernetes 負(fù)責(zé)管理集群資源,調(diào)度各項(xiàng)計(jì)算任務(wù)。
NoSQL數(shù)據(jù)庫(kù):為處理多樣、靈活的數(shù)據(jù)模型而生,如 HBase(列存儲(chǔ))、MongoDB(文檔存儲(chǔ))、Cassandra(寬列存儲(chǔ))。
* 消息/流處理:Apache Kafka 是處理實(shí)時(shí)數(shù)據(jù)流的消息隊(duì)列核心,常與 Flink 或 Spark Streaming 配合實(shí)現(xiàn)實(shí)時(shí)分析。
從Hadoop生態(tài)到以Spark、Flink為核心的現(xiàn)代架構(gòu),了解這些工具的基本定位是構(gòu)建技術(shù)知識(shí)地圖的第一步。
4. 認(rèn)識(shí)到云計(jì)算的關(guān)鍵作用
對(duì)于初學(xué)者和企業(yè)而言,云計(jì)算極大地降低了大數(shù)據(jù)的入門門檻。AWS、Azure、阿里云等主流云平臺(tái)提供了全面托管的大數(shù)據(jù)服務(wù)(如Amazon EMR、Azure HDInsight),讓你無(wú)需自行搭建和維護(hù)復(fù)雜的物理集群,即可按需使用存儲(chǔ)、計(jì)算和各類分析工具。理解云服務(wù)模型(IaaS, PaaS, SaaS)以及如何利用云平臺(tái)快速開展大數(shù)據(jù)項(xiàng)目,是現(xiàn)代大數(shù)據(jù)實(shí)踐的重要一環(huán)。
5. 明確技能發(fā)展與學(xué)習(xí)路徑
對(duì)于個(gè)人學(xué)習(xí)者,一個(gè)清晰的入門路徑至關(guān)重要:
- 基礎(chǔ)先行:扎實(shí)掌握 Linux 命令行操作、至少一門編程語(yǔ)言(Python 或 Scala 在大數(shù)據(jù)領(lǐng)域應(yīng)用廣泛)以及 SQL 知識(shí)。
- 核心突破:深入學(xué)習(xí)和實(shí)踐 Hadoop 和 Spark 的核心原理與編程。可以從單機(jī)偽分布式環(huán)境搭建開始,運(yùn)行簡(jiǎn)單的WordCount程序,逐步深入。
- 領(lǐng)域深入:根據(jù)興趣方向,選擇深入學(xué)習(xí) 數(shù)據(jù)倉(cāng)庫(kù)/湖倉(cāng)一體(如Hive)、實(shí)時(shí)計(jì)算(如Flink)、數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí)(MLlib)等特定領(lǐng)域。
- 項(xiàng)目實(shí)踐:理論結(jié)合實(shí)踐至關(guān)重要。嘗試在公共數(shù)據(jù)集或模擬業(yè)務(wù)數(shù)據(jù)上,完成一個(gè)從數(shù)據(jù)采集、處理、分析到可視化的小型端到端項(xiàng)目。
總而言之,大數(shù)據(jù)入門是一個(gè)系統(tǒng)工程。從理解核心概念開始,到把握技術(shù)生態(tài),再到結(jié)合云平臺(tái)進(jìn)行實(shí)踐,這五件事為你構(gòu)建了一個(gè)堅(jiān)實(shí)的學(xué)習(xí)框架。記住,關(guān)鍵在于保持好奇,動(dòng)手實(shí)踐,循序漸進(jìn)地在這個(gè)充滿機(jī)遇的領(lǐng)域中探索和成長(zhǎng)。



 宜興5G工廠實(shí)現(xiàn)零的突破 智慧賦能,大數(shù)據(jù)驅(qū)動(dòng)制造轉(zhuǎn)型駛?cè)搿翱燔嚨馈?/span>
宜興5G工廠實(shí)現(xiàn)零的突破 智慧賦能,大數(shù)據(jù)驅(qū)動(dòng)制造轉(zhuǎn)型駛?cè)搿翱燔嚨馈?/span>